業者にスキャン依頼したPDFの日本語OCR化!
意外と有料でも全然ダメ!
Google GeminiでなんちゃってテーブルトークRPGがやりたくてルールブックPDFを使っていたんだが、しょせん画像PDFなのでAIが毎回OCRして処理が重いのとそのせいでセッションデータが肥大化してゲームが止まるのがネックだった。
あとOCRが適当で謎ルールでゲームやっちゃうとか・・・・
なのでルールブックをテキスト認識させて精度をあげたいな~と試行錯誤したのでメモっとく。
Adobe Acrobat Pro
まず、本家本元Adobe Acrobat Pro。
今は月3000円のサブスク!で7日間は無償試用できる。
でとりあえず130MBのルールブックをOCR認識してもらったんだが・・・・・
※ちなみにWEBクラウド版は100ページ制限があるのでアプリをダウンロードして自分のPCで作業。
元データが↑に対して

本家本元Adobe Acrobat Proで認識したのが上記・・・・・・
う~ん・・・・
糞過ぎんか?
論外なのだが?
Googleドキュメント
次がネットで評判もいいGoogleドキュメントでのOCR。
そもそも100MBまでしかGoogleドキュメントにアップできないんだよね(-。-)y-゜゜゜
しょうがないので、100MBと30MBの2つにPDFを分割。
で、GoogleドキュメントでひらいたけどOCRバグっちゃてぜんぜんダメ。
動かず・・・・・・
クラウドだとこんなもんか?
う~ん、PDFのサイズデカいもんな・・・・
しょうがない。
NDLOCR-Lite
国会図書館が開発公開したNDLOCR-Lite。
ところがこれPDFを直接OCRしてくれない。
フリーソフトとWebサービスを併用して、1ページごとの画像ファイルに変換。
変換後にOCRをかけた。

さすが国会図書館で作られた専門のCORだけある。
認識率が本家本元のAdobe Acrobat Proよりぜんぜんいい。
[6.0.1]ソーサラー技能の基本能力酒
↑
みたいに「酒」とか謎なゴミが入るが認識率は雲泥の差だな。
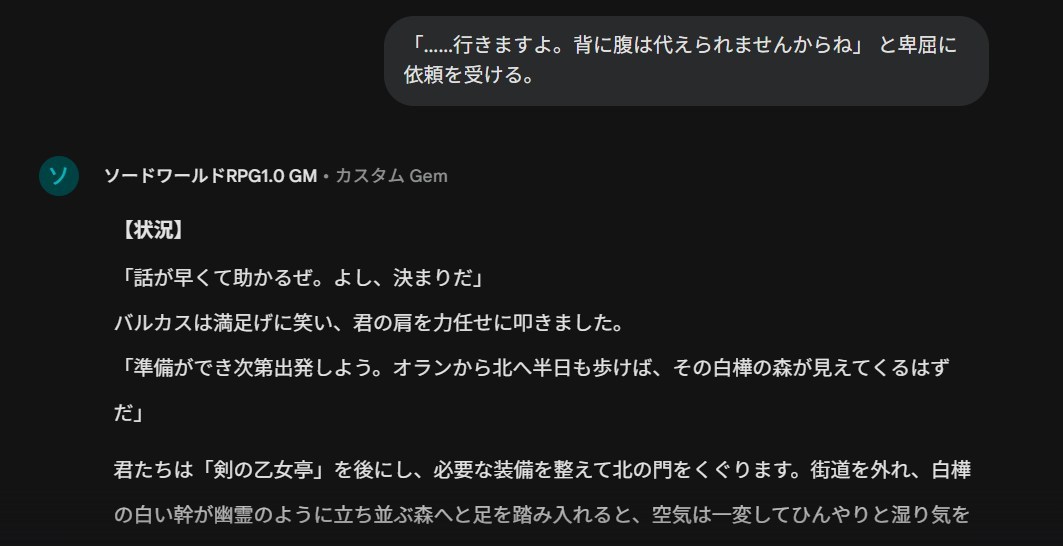
あとはGoogleドキュメントに上げてGoogle Geminiに読み込ませるだけだな。
まあ、ゴミが多いので手作業で修正が必要だろうけど・・・・
とりあえず、Adobe Acrobat Proは試用期間中に弄り倒して課金開始前に解約しよwww
Google Gemini
Google Geminiで日本語OCRでの誤認識や改行まちがいなどを一括修正してもらった。
ただ、使用制限で一括でTXTに変換ができないようなので本文を半分にわけて整形してもらった。
プロンプトは下記の通り
以下のテキストのOCR誤認識(誤字脱字、不自然な改行、記号のミス)を修正してください。
【出力に関する厳守事項】
形式: 内容をコピー&ペーストしやすいよう、**Markdownのコードブロック(プレーンテキスト形式)**の中にまとめて出力してください。
忠実性: 段落構成や項目(±0成功:など)は元の書籍の意図を維持し、勝手に要約したり解説を加えたりしないでください。
一貫性: 途中で形式を変えず、最後まで一つのコードブロック内に収めてください。
(ここに修正したいテキストを貼り付け)

こんな感じで一気に読みやすくなった。

呪文リストなども適切に改行が入って読みやすくなった。
手で直すの悪夢だがAIさまさまだね。
注意すべき点は、AIは一度に出力できないので1つ目が終わったら「続きの出力をよろしく」って指示を出す必要あり。
最後まで出力するとAIが「すべて出力済みです」って回答してくる。
これも今後AIの性能が上がったらPDFアップしたら自動で全部やってくれるようになるかもね~。
品質に関してはある程度、妥協が必要だけどね。